Screaming Frog SEO Spider: dé tool voor de echte SEO-ers
Ik maak wel eens het grapje dat SEO eigenlijk niets meer is dan trucjes en tools. Niet waar natuurlijk, maar gezien ik zelf SEO-consultant ben mag ik die wel maken. Ondanks dat er meer komt kijken bij SEO dan je standaard lijstje afwerken, is er toch een tool die je als echte SEO-er moet kennen. Namelijk Screaming Frog SEO Spider.
Screaming Frog heeft zoveel functies dat ik hem voor iedere website weer gebruik. Ik werk er nu twee jaar mee en blijf nieuwe dingen ontdekken. De handleiding voor alle functies van Screaming Frog staat gewoon online. In dit artikel geef ik daarom handige tips voor uitdagingen die je in de praktijk kan tegenkomen.

Hoe werkt Screaming Frog
Met Screaming Frog maak je een crawl van je website door de URL van je website erin te stoppen. De spider werkt net als de Google Bot door alle linkjes in je website te volgen. Als je orphan pages* in je website hebt, zullen deze niet naar boven komen. Dat is wel een belangrijke om te onthouden.
Nadat het crawlen klaar is laat de tool alle individuele pagina’s in je site zien. Je gebruikt hem voor het checken van de techniek maar bijvoorbeeld ook voor je Title Tags, Meta Descriptions, H1’s en H2’s.
* Een orphan page is een pagina die geen links vanaf andere pagina’s op de eigen website heeft.
Licentie
Ik begin direct met de eerste tip: Als je serieus bent over SEO, koop dan gewoon de licentie. De gratis versie heeft wat mij betreft teveel beperkingen. Zo kan je bijvoorbeeld niet meer dan 500 pagina’s crawlen, werkt de custom extractor niet en doet de ‘ignore robots.txt’ functie het ook niet. Do I need to say more?
404s uit Google Search Console controleren
De Google Search Console geeft aan dat je een flink aantal 404’s in je website hebt zitten. Oei, niet best natuurlijk. Deze moeten geredirect worden. Maar voordat je begint moet je ze controleren want het zou ook heel goed kunnen dat een paar gewoon een 200 status code hebben of al geredirect zijn en dus een 301 hebben. De Search Console loopt soms helaas wat achter.
Om ze niet allemaal handmatig na te hoeven lopen download je de lijst vanuit de Search Console. Volg daarna deze stappen:
- In het Excelbestand uit de Search Console bewaar je enkel de URLs in 1 kolom. Verder verwijder je
- Kopieer alle URLs en ga naar Screaming Frog
- Klik op ‘Mode’ > ‘List’ > ‘Upload List’ > ‘Enter Manually’
- Plak hier de URLs die je in stap 2 hebt gekopieerd
- Klik op ‘Next’ > ‘Ok’
- Screaming Frog crawlt nu alle handmatig ingevoerde URLs
- Als de tool klaar is verschijnen alle URLs met de status
- Verwijder alle 200 codes en 301s door met de rechter muisknop te klikken en vervolgens op ‘remove’.
- Nu heb je als het goed is alleen URLs over met 404
- Kies vervolgens bij ‘Filter’ voor HTML
- En klik vervolgens op ‘Exporteer’ en sla op als Excelbestand
- Start vervolgens het redirecten
Interne links opschonen; 301’s er tussenuit
Oké, ga maar even goed zitten voor deze want ik merk keer op keer weer dat dit een lastige is. Hoe gedetailleerd ik de instructies voor de websitebouwer ook maak.
Voordat we de ‘discussie’ gaan voeren of dit goed is voor SEO: ja, Google zegt dat het niets doet voor je rankings, toch merken wij steeds weer dat het wel werkt. Daarom deze fijne tip.
Ik begin met een uitleg hoe 301’s op interne links ontstaan en waarom je ze moet ‘opschonen’.
Stel je hebt in je website veel 404’s gehad en deze heb je keurig geredirect. Klaar is Kees, toch? Not quite! Want in heel veel gevallen (eigenlijk bijna altijd), worden interne links niet gewijzigd en wordt er dus nog steeds gelinkt naar de oude pagina die middels een redirect naar de nieuwe pagina gaat.
Als de bezoeker op de link klikt gaat hij dus netjes naar de nieuwste pagina. Echter, het is voor SEO niet goed want met iedere 301 ertussen gaat waarde verloren. EN-DAT-WILLEN-SEO’ERS-NIET
Wat gaan we dan doen? De interne links opschonen! Wees voorbereid want een leuk klusje is het niet.
- Klik op ‘Mode’ > ‘Spider’
- Vul de URL in en klik op ‘Start’

- De crawl start en de tool verzamelt alle pagina’s
- Kies bij ‘Filter’ voor ‘HTML’
- Als het mee zit dan heb je zoals bij ons maar één pagina met een 301 waar intern naartoe gelinkt wordt.
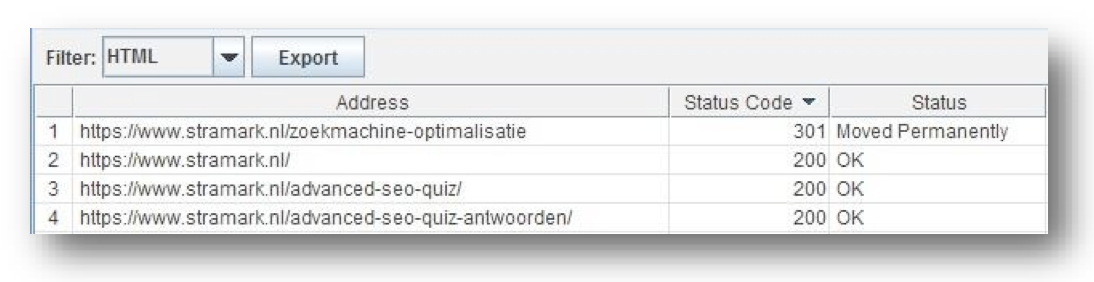
- Klik vervolgens op ‘Bulk Export’ > ‘All Inlinks’
- Sla het Excelbestand op en open het vervolgens
- Nu ga je het bestand opruimen zodat je er straks in kan werken
Excelbestand opruimen
- Sorteer kolom ‘Type’ en verwijder alle regels waar géén ‘HREF’ voor staat. Dus IMG, CSS en JS kunnen eruit. Dit maakt je lijst al een stuk
- Verwijder nu kolom ‘Type’. Die is niet meer
- Verwijder nu alles uit het bestand wat niet naar jouw website linkt. Sorteer hiervoor kolom ‘Destination’ op alphabet. Je linkt bijvoorbeeld ook naar YouTube, partners of andere websites. Je wilt enkel de interne links bewaren, de rest mag
- Sorteer nu kolom ‘Status’ en en laat de statuscode van hoog naar laag
- Bewaar voor dit onderdeel enkel de 301’s. Alle andere regels mogen
- Verwijder nu alle kolommen behalve ‘Source’ en ‘Destination’.
‘Source’ is de pagina waar de link staat. ‘Destination’ is de pagina waar naartoe gelinkt wordt maar die geredirect is.
Interne links opschonen
- Voeg nu een derde kolom toe die je de naam geeft: ‘Waar naartoe gelinkt moet worden’. Of iets in die trant.
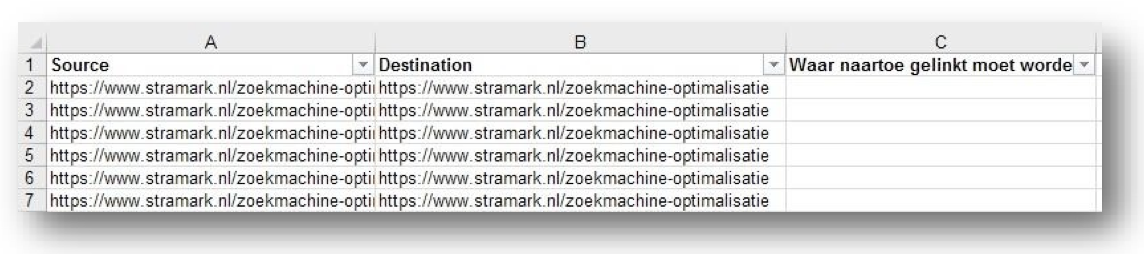
- In deze kolom vul je de juiste URLs heen. Dus de URL waar de Destination URL naartoe geredirect
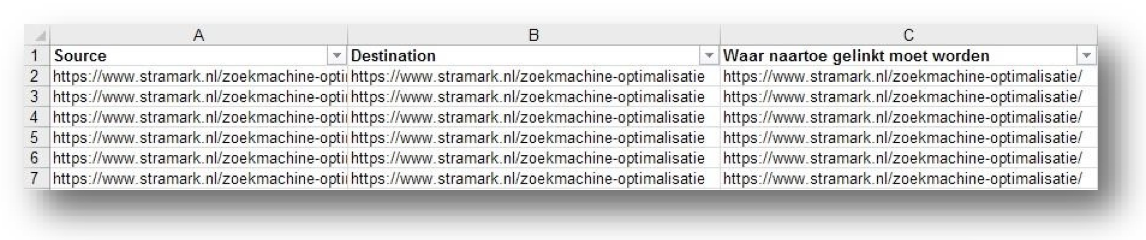
Nu heb je het opschonen voorbereid en kan je aan de slag.
- Bezoek op de website de pagina’s uit kolom ‘Source’ en zoek naar de links uit kolom ‘Destination’. Wijzig deze linkjes in de linkjes ‘Waar naartoe gelinkt moet worden’.
Als je kijkt naar bovenstaand voorbeeld wordt B dus vervangen door C.
Ik weet het, geen misselijk klusje als er veel links opgeschoond moeten worden. Maar trust me, het is de moeite waard.
Hreflang tags controleren
Bij onze klant Sendsteps (producent van Audience Response System), constateerde ik in de Search Console fouten in de Hreflang Tags en pagina’s zonder Hreflang Tags. Met de Custom Extraction functie van Screaming Frog kan je heel gemakkelijk een overzicht maken van alle Hreflang Tags in je website. Zo kan je bijvoorbeeld kijken op welke pagina’s tags missen of dat er naar de juiste URLs verwezen wordt.
Volg deze stappen:
- Tel eerst hoeveel Hreflang Tags je hebt. Dus hoeveel talen er
- Klik op ‘Configuration’ > ‘Custom’ > ‘Extraction’
- Kies vervolgens voor ‘XPath’
- Geef daarna in de linker kolom je custom extraction elementen een naam
- Vervolgens voer je (//*[@hreflang])[1] in de derde kolom in
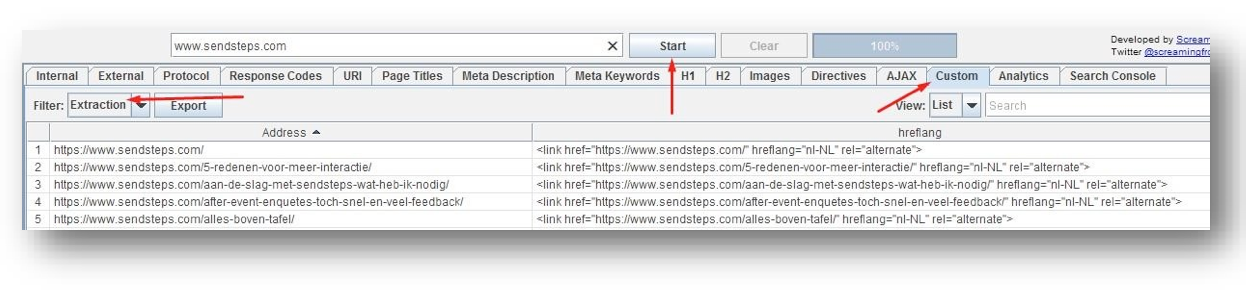
- Als laatste kies je voor ‘Extract HTML Element’ Dat ziet er zo uit:

- Klik nu op ‘Ok’
- Voer nu de URL bovenaan in de balk in en klik daarna op ‘Start’
- Klik in de tabs nu op ‘Custom’ en bij Filter voor ‘Extraction’
Je kan de verzamelde gegevens nu middels de ‘Export’ knop opslaan als Excelbestand.
Deze stappen zijn een belangrijk onderdeel van de Technische Zoekmachine Optimalisatie en door deze uit te voeren maak je al mooie eerste stappen.
Gerelateerde opleiding
Deel dit bericht
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond
15 Reacties
robin
Goed artikel Fenna.
Een van de mooiste dingen van Screaming Frog die je met Screaming Frog kunt doen is het eenvoudig scrapen van je de website van je concurrent. Prijs informatie bijvoorbeeld, of andere openbare informatie die je zelf niet hebt maar wel kunt gebruiken om technische specs van producten op je site aan te vullen etc.
Als je een klein budget hebt als SEO’er is dit de eerste tool die je moet aanschaffen.
Fenna
Bedankt voor je reactie Robin.
Mijn collega was laatst bezig met het verzamelen van prijs informatie m.b.v screaming frog. Hij deed dat ook met de custom extraction tool. Ontzettend handig en een goede aanvulling voor in dit lijstje, thanks!
Wilco Wietsma
Werkt de custom extraction tool van SF ook achter een login? Voor publiektoegankelijke websites gebruik ik namelijk https://www.import.io/, geweldige tool als je veel data automatisch en gestructureerd wil exporteren. Nadeel is wel dat deze tool dus niet pagina’s achter een login kan scrapen.
Fenna
Goede vraag Wilco.
SF werkt achter een login maar enkel achter een popup login. SF zal dan aangeven ‘Authentication required’. Mits je ‘Request Authentication’ hebt aangevinkt. Dit doe je via Configuration > Spider > Advanced. Uiteraard heb je dan wel username en wachtwoord nodig.
SF werkt niet achter login die ín de pagina zit.
Wat ook erg handig is dat je een staging website kan crawlen. Hierbij moet je wel de ‘Ignore robots.txt’ configuratie aanzetten. Dat doe je via: Configuration > Spider > Basic
Luuk
Hoi Fenna, wat een interessant artikel. Zelf gebruik ik SF ook en het kan idd een handige tool zijn. Heb jij ervaring met met 403 errors? Zou jij deze Ook redirecten of juist voorzien van een no index tag?
Gr. Luuk
Fenna
Bedankt Luuk!
Ik heb nog niet te maken gehad met 403’s. Wel weet ik dat een 403 ofwel ‘forbidden’ in principe geen foutmelding is maar bijvoorbeeld kan wijzen op een pagina met login. Ik zou er dan dus geen redirect op zetten. Een noindex is een optie maar echt noodzakelijk is het niet.
Marjet
Ik moest eigenlijk wel een beetje lachen om dit artikel. Misschien dat de echte content Kings (waar er helaas niet heel veel van zijn, wel zijn er teveel mensen die zich ‘SEO expert noemen’) weten waarom. ‘Screaming Frog SEO Spider’ hihi, daar ga je de oorlog niet mee winnen.
Fenna
Bedankt voor je waardevolle input Marjet.
Wel benieuwd waar in het artikel ik noem dat content niet belangrijk is. Echte SEO’ers hoef ik niet uit te leggen dat een goede SEO strategie een combinatie is van techniek en content.
Marjet
Hihi, dat laatste ‘goede SEO strategie een combinatie is van techniek en content’ zou je eens tegen iemand van Google moeten zeggen. Geen enkele kans dat je dan een voet tussen de deur krijgt als je daar gaat solliciteren.
Anoniem
@Marjet: Waarom zou je als SEO bij Google solliciteren?
Marjet
@Anoniem
Google heeft een ontzettende hekel aan al die zogenaamde SEO experts en consultants, geloof mij nou maar. SEO is bovendien een verouderde term. Oef moet ik dat nu echt uitleggen?
Anoniem
@Marjet: Ja, graag! Met referenties aub. Ben bijzonder geinteresseerd!
Sjoerd
SEO is nog altijd een samenspel van techniek, content en externe verwijzingen. Waarbij de nadruk op de content moet liggen. Daar ga je inderdaad de oorlog niet mee winnen met een tool als Screaming Frog. Maar, het helpt je wel eenvoudig op een rij te krijgen waar er hiaten zijn in een website.
@Marjet: het merendeel van de mensen dat bij Google in Europa werkt staan ver af van de techniek (dus development) het zijn verkopers en marketeers. Voornamelijk in de VS zitten developers die je inderdaad uitlachen wanneer je begint over SEO en met name als je jezelf presenteert als SEO expert. Maar doe niet alsof je de wijsheid in pacht hebt met een paar wazige semi-snuggerige reacties. Plus, SEO een verouderde term .. LOL
thomas
Don’t feed the troll guys. Goed artikel Fenna! Dank voor het delen van je kennis.
@anoniem
@Marjet Als je het zo goed weet. Wat voor tools gebruik je zelf?
@Fenna: Goed artikel, thnx voor de tips!